In mathematics the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points. K-Means is much faster if you write the update functions using operations on numpy arrays instead of manually looping over the arrays and updating the values yourself. It amounts to repeatedly assigning points to the closest centroid thereby using Euclidean distance from data points to a centroid.
The formula for distance between two points is shown below.
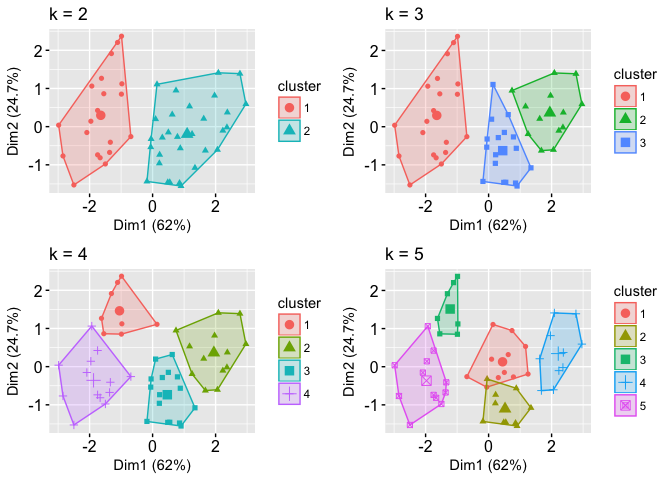
So the distance between these two points are the same than in previous step. So the distance between these two points are the same than in previous step. So choosing between k-means and hierarchical clustering is not always easy. K-means clustering aims to partition data into k clusters in a way that data points in the same cluster are similar and data points in the different clusters are farther apart.